本文将为您提供关于Wordcount--MapReduceexample--Mapper的详细介绍,同时,我们还将为您提供关于''com.example.mybatisplus.mapper.Pers
本文将为您提供关于Wordcount -- MapReduce example -- Mapper的详细介绍,同时,我们还将为您提供关于''com.example.mybatisplus.mapper.PersonMapper'' that could not be found.、(一)Hadoop之Mapreduce的基础入门实例WordCount详解、Hadoop 6、第一个 mapreduce 程序 WordCount、Hadoop MapReduce WordCount程序的三种API代码的实用信息。
本文目录一览:- Wordcount -- MapReduce example -- Mapper
- ''com.example.mybatisplus.mapper.PersonMapper'' that could not be found.
- (一)Hadoop之Mapreduce的基础入门实例WordCount详解
- Hadoop 6、第一个 mapreduce 程序 WordCount
- Hadoop MapReduce WordCount程序的三种API代码

Wordcount -- MapReduce example -- Mapper
Mapper maps input key/value pairs into intermediate key/value pairs. E.g. Input: (docID, doc) Output: (term, 1)
Mapper Class Prototype:
Mapper<Object, Text, Text, IntWritable>
// Object:: INPUT_KEY
// Text:: INPUT_VALUE
// Text:: OUTPUT_KEY
// IntWritable:: OUTPUT_VALUE
Special Data Type for Mapper
IntWritable
A serializable and comparable object for integer. Example:
private final static IntWritable one = new IntWritable(1);
Text
A serializable, deserializable and comparable object for string at byte level. It stores text in UTF-8 encoding. Example:
private Text word = new Text();
Hadoop defines its own classes for general data types. -- All "values" must have Writable interface; -- All "keys" must have WritableComparable interface;
Map Method for Mapper
Method header
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException
// Object key:: Declare data type of input key;
// Text value:: Declare data type of input value;
// Context context:: Declare data type of output. Context is often used for output data collection.
Tokenization
// Use Java built-in StringTokenizer to split input value (document) into words:
StringTokenizer itr = new StringTokenizer(value.toString());
Building (key, value) pairs
// Loop over all words:
while (itr.hasMoreTokens()) {
// convert built-in String back to Text:
word.set(itr.nextToken());
// build (key, value) pairs into Context and emit:
context.write(word, one);
}
Map Method Summary
Mapper class produces Mapper.Context object, which comprise a series of (key, value) pairs
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
Overview of Mapper Class
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}

''com.example.mybatisplus.mapper.PersonMapper'' that could not be found.
通常有两种原因,配置原因,或者是 mapper 相关文件,mapper.java 或 mapper.xml 内部错误
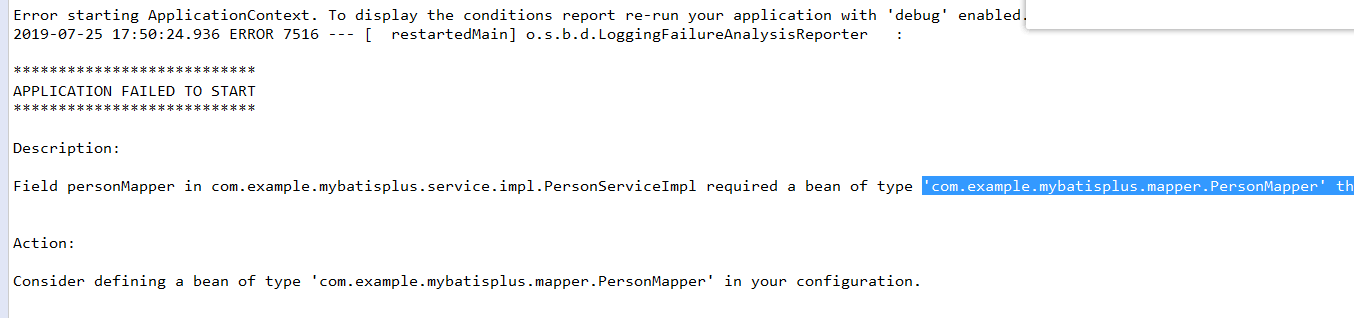
如果是配置原因
解决方式 1
统一配置 mapper
//import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.example.mybatisplus.mapper") //把这个加上,别写上正确的路径,如果是模块化一般路径为@MapperScan("com.kfit.*.mapper") public class Application {
public static void main(String[] args){
System.out.println("hahahaha");
SpringApplication.run(Application.class, args);
}
}解决方式 2
每个 mapper 文件配置 @Mapper
package com.example.mybatisplus.mapper;
//import org.apache.ibatis.annotations.Mapper;
import com.baomidou.mybatisplus.mapper.BaseMapper;
import com.example.mybatisplus.entity.Person;
@Mapper //每个文件配置这个
public interface PersonMapper extends BaseMapper<Person> {
Integer listCount();
Person findPersonById(Integer id);
}两者可以结合使用
Hadoop之Mapreduce的基础入门实例WordCount详解")
(一)Hadoop之Mapreduce的基础入门实例WordCount详解
Mapreduce初析
Mapreduce是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input)。mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而我们程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。

Mapreduce的基础实例
讲解mapreduce运行原理前,首先我们看看mapreduce里的hello world实例WordCount,这个实例在任何一个版本的hadoop安装程序里都会有。
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
*
* 描述:WordCount explains by York
* @author Hadoop Dev Group
*/
publicclass WordCount {
/**
* 建立Mapper类TokenizerMapper继承自泛型类Mapper
* Mapper类:实现了Map功能基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
/**
* IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为int,String 的替代品。
* 声明one常量和word用于存放单词的变量
*/
privatefinalstatic IntWritable one =new IntWritable(1);
private Text word =new Text();
/**
* Mapper中的map方法:
* void map(K1 key, V1 value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* Context:收集Mapper输出的<k,v>对。
* Context的write(k, v)方法:增加一个(k,v)对到context
* 程序员主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
* write方法存入(单词,1)这样的二元组到context中
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr =new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result =new IntWritable();
/**
* Reducer类中的reduce方法:
* void reduce(Text key, Iterable<IntWritable> values, Context context)
* 中k/v来自于map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum =0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
publicstaticvoid main(String[] args) throws Exception {
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf =new Configuration();
String[] otherArgs =new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length !=2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job =new Job(conf, "word count"); //设置一个用户定义的job名称
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为job设置输出路径
System.exit(job.waitForCompletion(true) ?0 : 1); //运行job
}
}WordCount逐行解析
- 对于map函数的方法:
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}这里有三个参数,前面两个Object key, Text value 就是输入的 key 和 value ,第三个参数Context context这是可以记录输入的key和value,例如:context.write(word, one)。
- 对于reduce函数的方法:
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}reduce函数的输入也是一个 key/value 的形式,不过它的value是一个迭代器的形式 Iterable<IntWritable> values ,也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。至于计算的逻辑则需要程序员编码实现。
- 对于main函数的调用:
首先是
Configuration conf = new Configuration();运行MapReduce程序前都要初始化Configuration,该类主要是读取MapReduce系统配置信息,这些信息包括hdfs还有MapReduce,也就是安装hadoop时候的配置文件例如:core-site.xml、hdfs-site.xml和mapred-site.xml等等文件里的信息,有些童鞋不理解为啥要这么做,这个是没有深入思考MapReduce计算框架造成,我们程序员开发MapReduce时候只是在填空,在map函数和reduce函数里编写实际进行的业务逻辑,其它的工作都是交给MapReduce框架自己操作的,但是至少我们要告诉它怎么操作啊,比如hdfs在哪里,MapReduce的jobstracker在哪里,而这些信息就在conf包下的配置文件里。
接下来的代码是:
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}If的语句好理解,就是运行WordCount程序时候一定是两个参数,如果不是就会报错退出。至于第一句里的GenericOptionsParser类,它是用来解释常用hadoop命令,并根据需要为Configuration对象设置相应的值,其实平时开发里我们不太常用它,而是让类实现Tool接口,然后再main函数里使用ToolRunner运行程序,而ToolRunner内部会调用GenericOptionsParser。
接下来的代码是:
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不累述了,一个是这个job的名称。
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
第三行和第五行就是装载map函数和reduce函数实现类了,这里多了个第四行,这个是装载Combiner类,这个类和mapreduce运行机制有关,其实本例去掉第四行也没有关系,但是使用了第四行理论上运行效率会更好。
接下来的代码:
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);这个是定义输出的 key/value 的类型,也就是最终存储在 hdfs 上结果文件的 key/value 的类型。
最后的代码是:
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);第一行就是构建输入的数据文件,第二行是构建输出的数据文件,最后一行如果job运行成功了,我们的程序就会正常退出。

Hadoop 6、第一个 mapreduce 程序 WordCount
1、程序代码
Map:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] words = StringUtils.split(value.toString(), '' '');
for(String word : words){
context.write(new Text(word), new IntWritable(1));
}
}
}Reduce:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
public class wordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text arg0, Iterable<IntWritable> arg1,Context arg2)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable i : arg1){
sum += i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}Main:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
Configuration config = new Configuration();
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("wordCount");
job.setJarByClass(RunJob.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(wordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/usr/input/"));
Path outPath = new Path("/usr/output/wc/");
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
Boolean result = job.waitForCompletion(true);
if(result){
System.out.println("Job is complete!");
}else{
System.out.println("Job is fail!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
2、打包程序
将 Java 程序打成 Jar 包,并上传到 Hadoop 服务器上(任何一台在启动的 NameNode 节点即可)
3、数据源
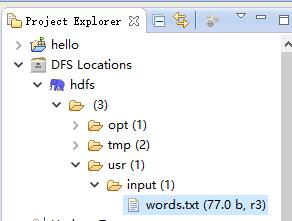
数据源是如下:
hadoop java text hdfs
tom jack java text
job hadoop abc lusi
hdfs tom text将该内容放到 txt 文件中,并放到 HDFS 的 /usr/input (是 HDFS 下不是 Linux 下),可以使用 Eclipse 插件上传:
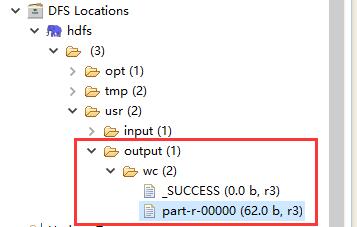
4、执行 Jar 包
# hadoop jar jar路径 类的全限定名(Hadoop需要配置环境变量)
$ hadoop jar wc.jar com.raphael.wc.RunJob执行完成以后会在 HDFS 的 /usr 下新创建一个 output 目录:
查看执行结果:
abc 1
hadoop 2
hdfs 2
jack 1
java 2
job 1
lusi 1
text 3
tom 2完成了单词个数的统计。

Hadoop MapReduce WordCount程序的三种API代码
旧版API:
package com.chenjun.MRstudy.oldapi;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class Wcmr {
private static final String INPUT_PATH = "/test/in/wc.txt";
private static final String OUTPUT_PATH = "/test/out/wcresult";
public static class MyMapper extends MapReduceBase implements Mapper<LongWritable,Text,Text,IntWritable>{
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String[] splitArray = value.toString().split(" ");
for(String s : splitArray){
output.collect(new Text(s), new IntWritable(1));
}
}
}
public static class MyReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>{
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while(values.hasNext()){
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(Wcmr.class);
conf.setJobName("wc");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MyMapper.class);
conf.setCombinerClass(MyReducer.class);
conf.setReducerClass(MyReducer.class);
conf.setNumReduceTasks(1);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(conf, new Path(OUTPUT_PATH));
JobClient.runJob(conf);
}
}新版API
package com.chenjun.MRstudy.newapi;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCountNewApi {
private static final String INPUT_PATH = "/test/in/wc.txt";
private static final String OUTPUT_PATH = "/test/out/wcresult";
public static class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
public void map(LongWritable key,Text value, Context context)
throws IOException,InterruptedException{
String line = value.toString();
String[] strArray = line.split(" ");
for(int i=0; i< strArray.length; i++){
context.write(new Text(strArray[i]), new IntWritable(1));
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException,InterruptedException{
int sum = 0;
for(IntWritable intWritable : values){
sum ++;
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) {
try {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountNewApi.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
boolean status = job.waitForCompletion(true);
if(status){
System.exit(0);
}else{
System.exit(1);
}
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}类 extends Configured implements Tool 形式的API
package com.chenjun.MRstudy.toolrun;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WorldCountUsingToolRunner extends Configured implements Tool {
private final static IntWritable one = new IntWritable(1);
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strArray = line.split(" ");
for(int i=0; i< strArray.length; i++){
context.write(new Text(strArray[i]), new IntWritable(1));
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int cnt = 0;
for(IntWritable iw : values) {
cnt += iw.get();
}
context.write(key, new IntWritable(cnt));
}
}
public int run(String[] allArgs) throws Exception {
Job job = Job.getInstance(getConf());
job.setJarByClass(WorldCountUsingToolRunner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setNumReduceTasks(1);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
String[] args = new GenericOptionsParser(getConf(), allArgs).getRemainingArgs();
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
ToolRunner.run(configuration,new WorldCountUsingToolRunner(), args);
}
}
我们今天的关于Wordcount -- MapReduce example -- Mapper的分享就到这里,谢谢您的阅读,如果想了解更多关于''com.example.mybatisplus.mapper.PersonMapper'' that could not be found.、(一)Hadoop之Mapreduce的基础入门实例WordCount详解、Hadoop 6、第一个 mapreduce 程序 WordCount、Hadoop MapReduce WordCount程序的三种API代码的相关信息,可以在本站进行搜索。
本文标签:




